1. Real-Time Speech Translation
VideoTranslatorAI delivers real-time speech translation with live captions and audio in multiple languages—perfect for meetings, events, and global teams.
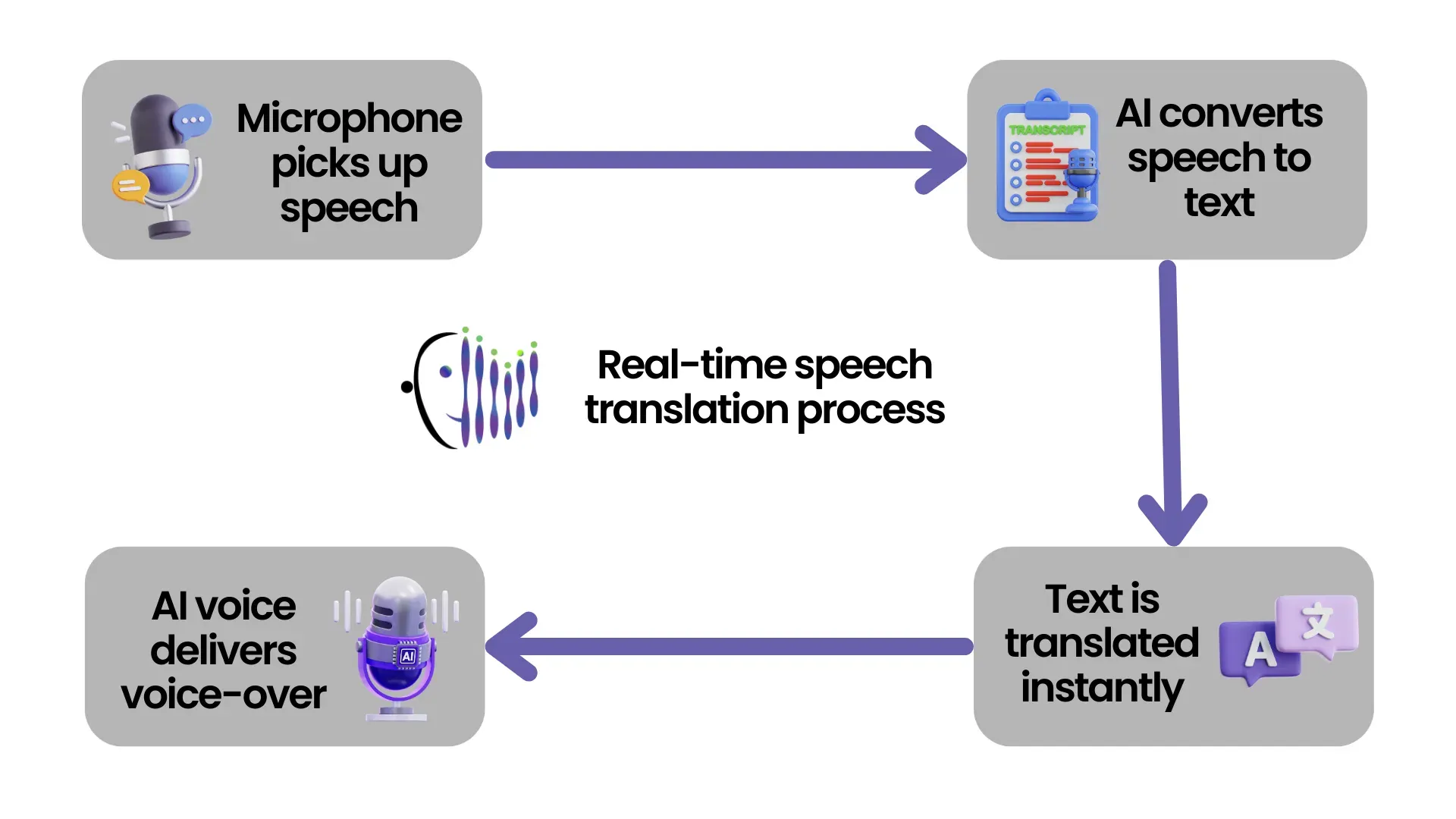
Real-time speech translation is the core capability of VideoTranslatorAI, allowing people who speak different languages to communicate naturally and instantly. As each participant speaks, their speech is transcribed, translated, and spoken aloud in the listener’s preferred language using neural voice synthesis. Translations are also shown as live captions.
The experience is designed to feel conversational — with low latency and continuous flow. Instead of waiting for a full sentence to be spoken, the system begins translating mid-sentence. This helps maintain the rhythm of dialogue, particularly in high-stakes or fast-moving conversations.
Real-time translation is available in three interaction modes: In-Person, Video Call, and Broadcast. Each mode is tailored to a specific context — for example, a face-to-face consultation at a help desk, a multilingual team meeting online, or a live public event where one speaker addresses a diverse audience.
Under the hood, the system combines automatic speech recognition (ASR), machine translation (MT), and neural text-to-speech (TTS) into a single pipeline. Custom glossaries and prompt tuning can be layered on top to reflect the terminology and tone your organisation prefers. The result is an AI-powered translator that sounds clear, relevant, and human.